ChatGPT, un allié pour la réutilisation des comptes-rendus de radiologie
Depuis moins de deux ans, la sortie de ChatGPT, un grand modèle de langage (Large Language Models, ou LLM), bouleverse le traitement et la génération de texte, et offre des perspectives passionantes en médecine. En radiologie, ChatGPT a déjà été utilisé pour structurer des comptes-rendus de manière automatique (1), ou extraire des données d’un grand nombre de comptes-rendus afin de créer des bases de données (2). Cependant, peu de travaux ont été faits sur des comptes-rendus réels rédigés en pratique courante, et aucun travail n’existe à ce jour sur des comptes-rendus de radiologie en langue française. Nous avons utilisé Vicuna, un modèle de langage open-source pour extraire des informations d’IRM cérébrales réalisées en urgence pour céphalées, et présenté ce travail au congrès européen de radiologie qui s’est tenu à Vienne du 28 février au 3 mars 2024.

Ce travail est né d’une question clinique : l’augmentation du nombre d’IRM pour céphalées demandées en urgence dans notre centre, et la frustration des radiologues devant un rendment diagnostique perçu comme faible. Les céphalées sont responsables d’environ 4 % des consultations aux urgences, soit environ 450.000 patients par an en France. Elles peuvent témoigner de pathologies sévères (thrombose veineuse cérébrale, dissection vasculaire, etc.) que seule l’imagerie peut éliminer. L’utilisation de l’imagerie pour les céphalées est en augmentation en Europe et aux Etats-Unis, notamment l’IRM, plus performante pour les diagnostics difficiles et non irradiante. A la suite de la prise en charge aux urgences, 95 % des patients retournent à domicile avec un diagnostic de céphalées bénignes. Dans ce contexte, nous avons voulu estimer le taux de positivité de l’IRM cérébrale pour céphalées dans notre centre spécialisé, afin d’évaluer la pertinence de cet examen coûteux pour un symptôme le plus souvent bénin.
Il n’existe actuellement pas d’outil prêt à utiliser pour automatiser la revue des dossiers afin d’en extraire des informations. Ce genre de travail nécessite donc une revue rétrospective des dossiers par des médecins radiologues, dans un environnement de travail déjà frappé par un manque de temps. Nous avons fait l’hypothèse qu’un modèle de langage de type ChatGPT pourrait nous aider à automatiser ce genre de tâche. Pour l’ensemble de ce travail, et pour nos travaux à venir, nous utilisons des modèles open-source, c’est à dire accessible gratuitement en ligne, et pouvant être téléchargés, utilisés et modifiés à volonté sur un ordinateur, sans communication de données à des serveurs tiers. Cet avantage est décisif : l’utilisation de ChatGPT nécessite de transmettre à OpenAI tous les dossiers médicaux à traiter, ce qui n’est pas compatible avec la sécurité des données de santé. Les modèles open-source, à l’inverse, garantissent le respect des données critiques. Il s’agissait donc de faire revoir tous les dossiers éligibles par des radiologues experts, et de faire traiter par un modèle de langage les mêmes dossiers, afin d’en calculer la précision de ses classifications.
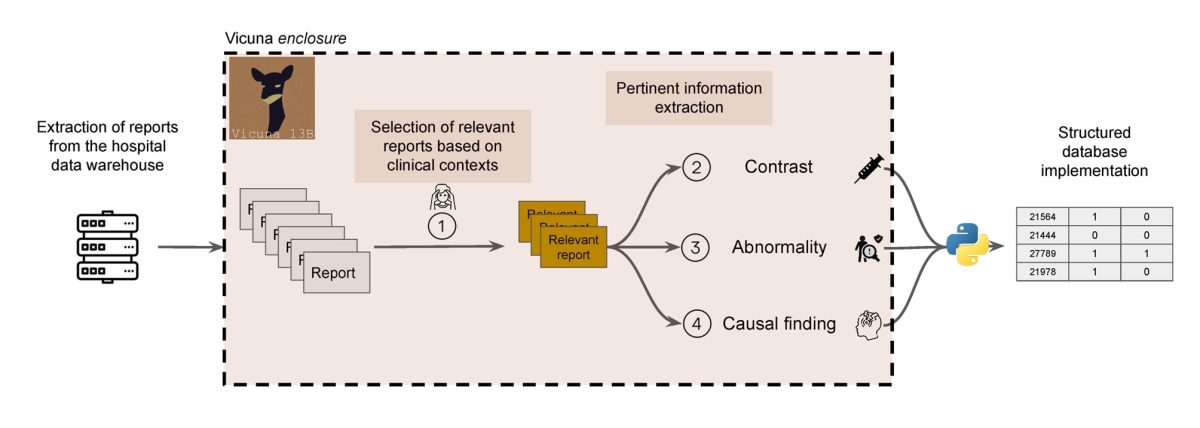
Figure 1 : Flux de travail de l’extraction d’information avec Vicuna
Nous avons revu manuellement les 2398 IRM cérébrales réalisées aux urgences pour céphalées en 2022 au CHU de Lille. Parmi celles-ci, 595 étaient réalisées pour céphalées (25%). Parmi celles-ci, les deux tiers (62%) étaient normales. Parmi les anomalies retrouvées, 40 % étaient jugées comme incidentelles par les neuroradiologues experts. Dans l’ensemble, 136 IRM retrouvaient une anomalie potentiellement à l’origine des céphalées, soit un taux de positivité à 23 %.
Vicuna, le modèle que nous avons utilisé pour ce travail, a pu identifier les examens réalisés pour céphalées avec une précision de 99 % en lisant l’indication de l’examen. Il a classé les examens comme étant normaux ou anormaux d’après leur conclusion avec une précision de 97 %. Enfin, il a classifié les anomalies retrouvées comme étant causales ou incidentelles avec une précision de 82 %.
Nous avons donc montré qu’un modèle de langage de type ChatGPT, mais ayant l’avantage d’être open-source, pouvait traiter des compes-rendus de radiologie en langue française rédigés au cours de la pratique courante, pour en extraire des informations médicales pertinentes. S’il avait des performances quasi-parfaites pour extraire l’indication de l’examen et classer les examens en normal/anormal, il était plus difficile pour lui de distinguer les anomalies pouvant être responsables de céphalées des anomalies incidentelles, une tâche difficile, même pour des radiologues entraînés.
Chaque jour, de nouveaux modèles de langage paraissent, toujours plus performants. Il est probable qu’ils deviennent des alliés pour les radiologues, en automatisant des tâches longues et répétitives, comme la revue rétrospective de comptes-rendus à la recherche d’indications précises, ou d’examens anormaux. De récents travaux montrent aussi que leur maîtrise du langage pourrait leur faire jouer un rôle dans l’amélioration de la qualité des comptes-rendus, et de leur capacité à transmettre une information adaptée aux correspondants médicaux ainsi qu’aux patients (3).
La recherche sur les applications des modèles de langage en radiologie promet donc d’être passionante et de rendre la vie des radiologues plus facile, dans un futur proche. Il est donc critique d’y consacrer des efforts pour que les solutions futures intègrent les spécificités des comptes-rendus en langue française et les attentes de la communauté des radiologues français.
Réferences
1. Adams LC, Truhn D, Busch F, et al. Leveraging GPT-4 for Post Hoc Transformation of Free-Text Radiology Reports into Structured Reporting: A Multilingual Feasibility Study. Radiology. 2023;230725. doi: 10.1148/radiol.230725.
2. Fink MA, Bischoff A, Fink CA, et al. Potential of ChatGPT and GPT-4 for Data Mining of Free-Text CT Reports on Lung Cancer. Radiology. Radiological Society of North America; 2023;308(3):e231362. doi: 10.1148/radiol.231362.
3. Amin KS, Davis MA, Doshi R, Haims AH, Khosla P, Forman HP. Accuracy of ChatGPT, Google Bard, and Microsoft Bing for Simplifying Radiology Reports. Radiology. Radiological Society of North America; 2023;309(2):e232561. doi: 10.1148/radiol.232561.